AI Observability In Enterprise

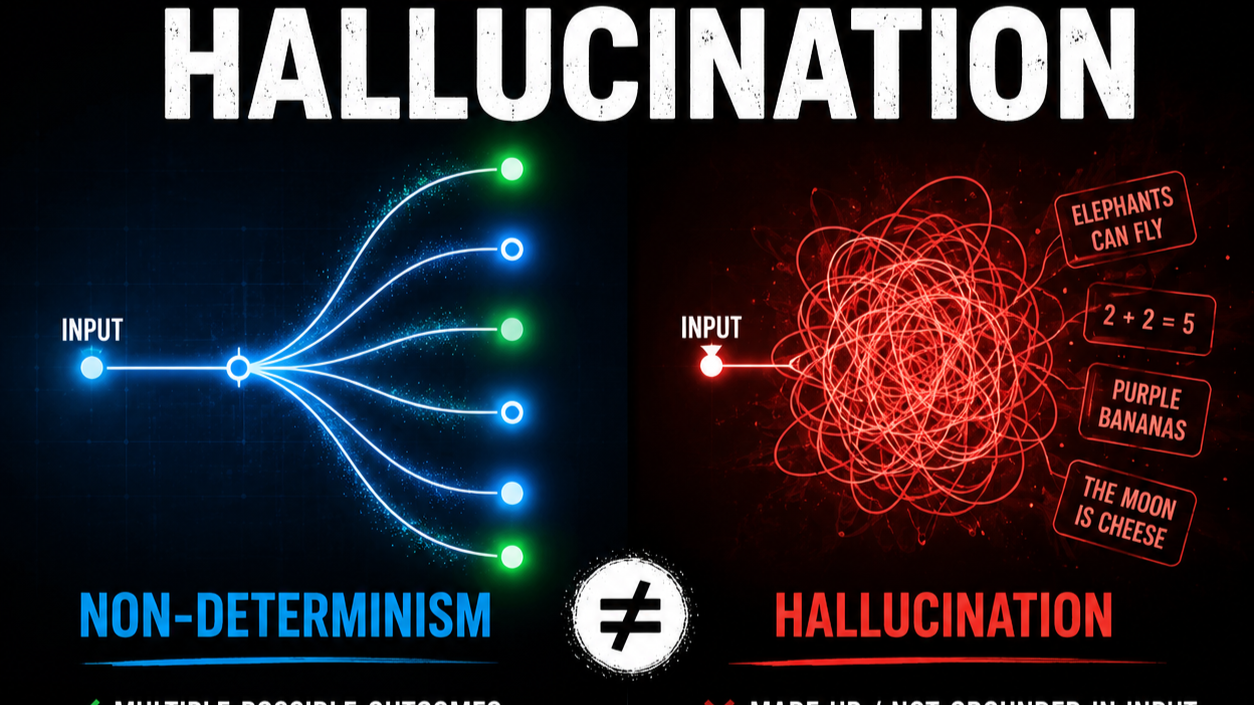
Everyone says "monitor your AI in production". Almost nobody draws the system that does it. "Add Observability" is a slogan until you can say exactly what gets captured, where it lands, how long it lives, and who reads it.
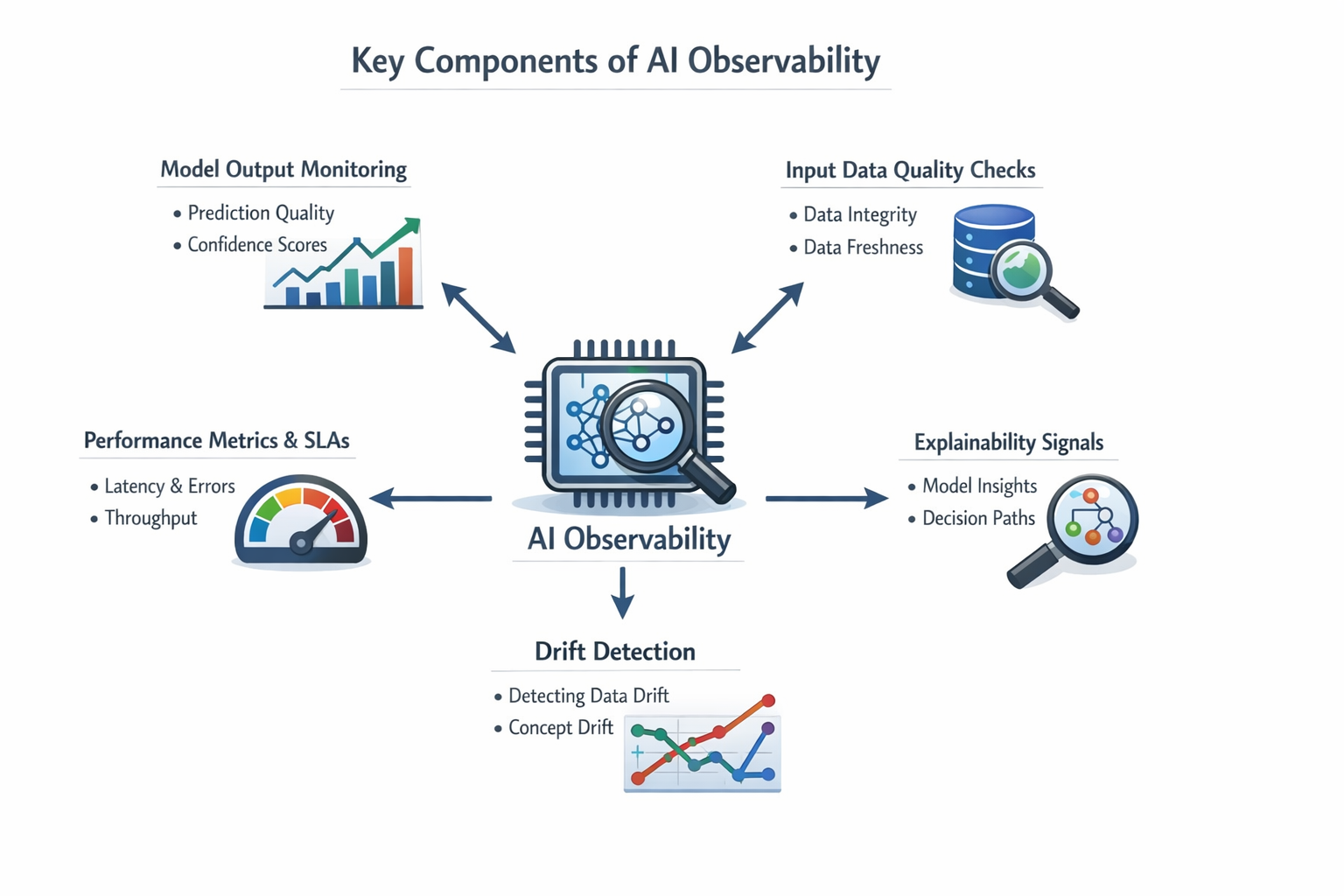
This is an architecture breakdown - capture in the request path, fan-out into purpose-built storage tiers, and four very different consumers reading off them. The headline: AI observability isn't one thing. It's five signals with five retention policies feeding four jobs, and the regulator-facing ones look nothing like the dashboard-facing ones.
AI observability is not "a dashboard". It's a capture-and-retention architecture: each signal (logs, metrics, traces, raw prompts, audit records) has a different consumer, a different retention window, and a different blast radius if you get it wrong.