How LLM Works Under the Hood
· 7 min read

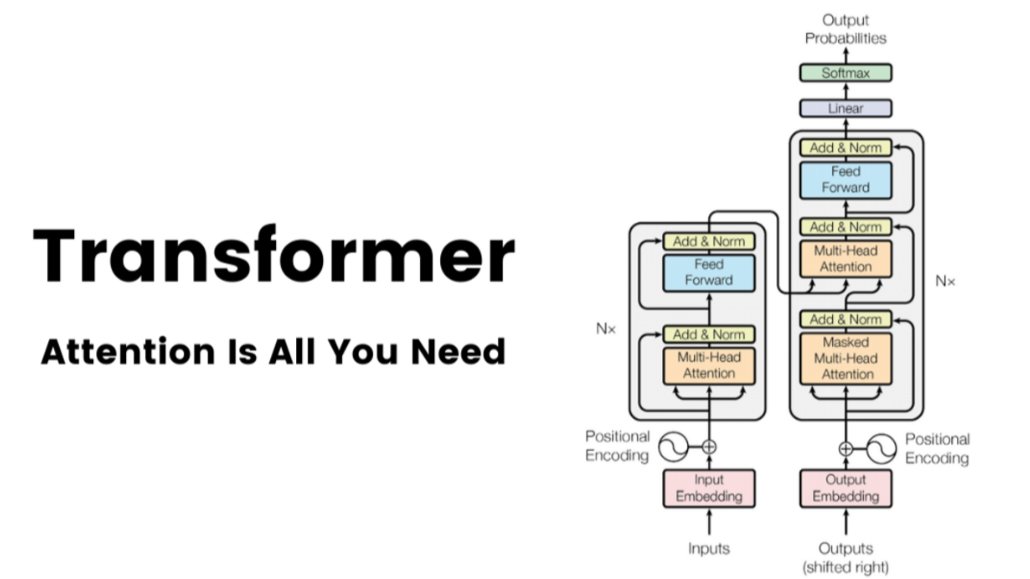
Most discussions about LLMs focus on prompts, tools, and frameworks. However, few explain how the model actually works under the hood and why that matters when building real systems.
This is a 20,000-ft view of the LLM lifecycle in four stages.
The big picture: one model, four stages.
A model's whole life is just four stages. The shape and vocabulary are fixed first; training only fills in the values, and inference is read-only and never learns.
| Stage | What happens | Key ideas |
|---|---|---|
| Before | Decide the blueprint | Architecture dials set the shape, tokenizer builds the vocabulary, and parameter count is fixed. |
| During | Fill in the values | Random weights become meaningful through training: a four-step loop run millions or trillions of times. |
| Alignment | Make it helpful | Show good examples (SFT) and teach which answers are better (RLHF/DPO). |
| After | Run it, read-only | Weights are frozen (no learning); inference traverses the model geometry one token at a time. |
TAKEAWAY
Shape + vocabulary are fixed first. Training only fills the values. Inference never learns.